
Often you have to operate with flattened data that in reality contains multiple levels of hierarchy. For example it can come as a result of several SQL JOIN statement and look like this:

In this example data consist of static root column, region, site, type and state. And the data has clearly defined hierarchy (e.g. Region “India” has site “Bangalore”, site “Bangalore” has types “Application” and “Area”, type “Application” has states “N/A” and “Testing”).
To load this data into Infragistics UltraWebTree I put together a small procedure:
Sub PopulateNavigatorTree(ByVal i_dtTable As DataTable, ByVal i_aNodes As Nodes, ByVal i_iGroupNo As Integer, ByVal i_sFilter As String)
Dim oNode As Node
Dim aFilteredData = From row As DataRow In i_dtTable _
Where row.Field(Of String)(i_iGroupNo - 1) = i_sFilter _
Select row
Dim aQuery = From row In aFilteredData _
Select row.Field(Of String)(i_iGroupNo) Distinct
For Each sGrName As String In aQuery
oNode = i_aNodes.Add(sGrName)
If i_iGroupNo < i_dtTable.Columns.Count - 1 Then
PopulateNavigatorTree(aFilteredData.CopyToDataTable, oNode.Nodes, i_iGroupNo + 1, sGrName)
End If
Next
End Sub
As parameters it accepts DataTable with flat data, collection of tree nodes (initially empty), group number (or column number in the table) and field data as a filter. So using data example from above and data table named dtData and tree named xuwtTree the call to the function will be:
PopulateNavigatorTree(dtData, xuwtTree.Nodes, 1, "GR")
First LINQ query (Lines 5-7) selects only those DataRows from the DataTable that belong to hierarchy of one level above current (using input parameter as a filter). The second query (lines 9-10) selects distinct field names from the current level. Then the loop (Lines 12-19) iterates thru those names, adding them to tree node collection (Line 13). And if there’re more groups to process (table has more columns) function calls itself recursively (Lines 15-17), passing filtered data, created by LINQ query previously and now converted back to data table, child Nodes collection of newly created node (currently empty), column number incremented by 1 and current field data as filter. The result:
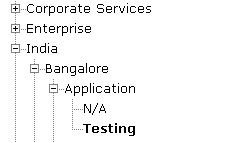
This approach assumes that there is on common root element (“GR” in this case) in the flat data and uses Infragistics UltraWebTree as target control, but it can easly be adapted to other scenarios and controls.
sir i’m doing this same type of application but i want in C#.i do no vb can you pls convert the coding in to c#.replay me soon
regards
deva